|
itrace
Instrumented Trace
|


|
|
itrace
Instrumented Trace
|
|
The Instrumented Trace (itrace) library enables its users to monitor events in parallel on multiple domains of Qualcomm devices.
With the itrace library, a user can register a set of events and identify one or more code sections of interest during which to monitor the registered events. Additionally, the itrace library allows to configure a sampler that monitors registered events periodically. Please note that itrace is currently intended for debug and development on test devices.
The values of the monitored events are post-processed according to their respective itrace_processing_mode_t before being rendered on timelines and in statistic reports. Timelines are captured in trace files in a json format viewable with Perfetto.
Here is an example of trace output produced by itrace.
The itrace library may be used with all LA and LE devices supported in the Hexagon base SDK. For support on additional targets, refer to the relevant Hexagon SDK addon.
The itrace_set_target_files APIs should be used to specify the output Output file types itrace will generate. By default, all output types are generated by itrace. Each output report provides a different understanding of resource utilization. All output reports are generated in the folder itrace_results.
Note: When interpreting any of the itrace output files, it is important to remember that most events count resources are shared accross the entire domain. As a result, when monitoring an event on a given thread, contributions from other threads will also be counted. In other words, when a function reports a global event count, this count combines contributions from all threads that ran in parallel with the monitored function.
The json output is a text-based file output containing timeline data. This file should be open with Perfetto from your Chrome browser. The combined reports show the following information:
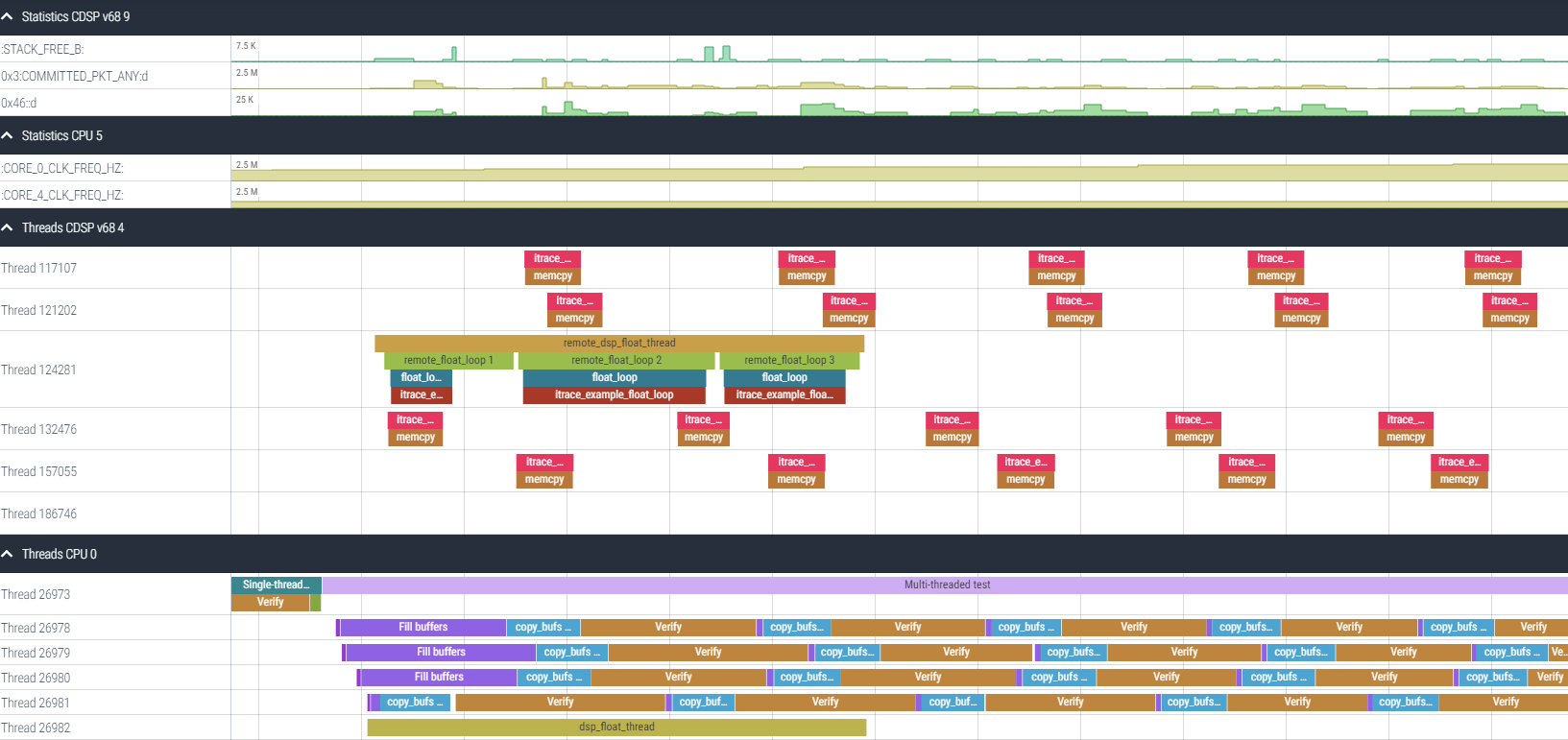
Domain Statistics rows in the timeline show post-processed event values whenever an event is measured.
Below is an example of CDSP statistics expressed in the timeline.

And below is an example of CPU statistics expressed in the timeline.

Events are measured when either of these scenarios occur:
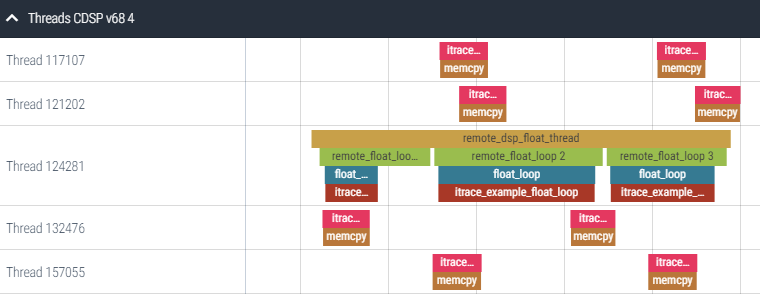
Domain Threads rows in the timeline show when a given section is active. When sections are monitored within other sections, section activities are stacked on top of each other. Section sections may be up to 5 levels deep.
Here is an example of a DSP timeline showing CDSP thread activity.
In parallel with the DSP timeline, the itrace output will show the CPU thread activity as illustrated below.

Section metrics report the post-processed event values captured at the start and end of a section, or by how much these metrics increased over the duration of the section. Section statistics are accessible from the timeline by clicking on each section.
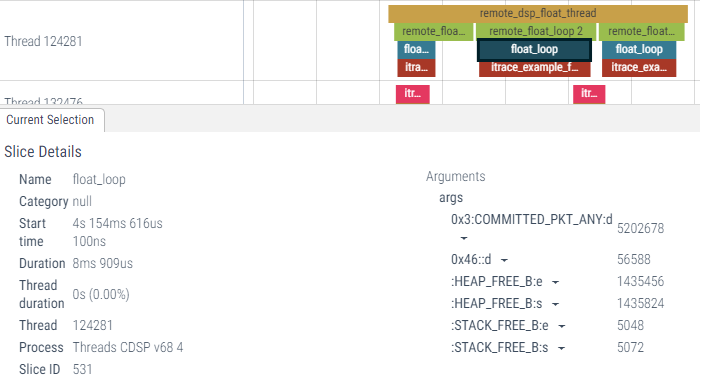
Section statistics are also reported separately in CSV files that may be open with any text editor or, preferably, a tabulator viewer like Excel.

Note: When specifiying the start or end of a section, the client may request the measured events to be returned as part of the API call. This gives additional flexibility to the user who may need access to these values programatically as well.
itrace may also generate text files compatible with Flamegraph. These text files are generated in a tmp folder of the itrace output folder as these are only intermediary files. One file is generated for each monitored event with a ITRACE_PM_DELTA or ITRACE_PM_NORMALIZED processing mode. Two additional files are generated:
The itrace example illustrates how these text file may be post-processed by Flamegraph to generate Flamegraph or Icicle output reports.
In order to generate these reports, you will need to download the Flamegraph project and run the Perl script flamegraph on one of the output from itrace. For example:
flamegraph.pl itrace_example_fg__0x50_COMMITTED_FPS.txt --title "Flamegraph for event 0x50_COMMITTED_FPS" --countname COMMITTED_FPS > itrace_example_flamegraph_0x50_COMMITTED_FPS.svg
will generate a Flame graph showing the stack trace of all code sections profiled with itrace for system-level event COMMITTED_FPS (counting the number of floating-point operations). Adding --inverted to the command line will generate an Icicle output instead.

As shown on the figure above, hovering over each entry will provide details about that section. The user may also click on any section to zoom on the call stack for that specific code section.
This view illustrates the fact that PMU counts should be interpreted with care: the PMU events currently measured by itrace are system-wide events. This means that when a given code section is profiled, all threads running in parallel during that time will also contribute to the count of the event being monitored. This is why, in the example above, memcpy is reported as having consummed floating-point operations even though that function alone does not consume any floating-point operation.
The Flamegraph output for the time (TIME_NS) metric is useful to understand at a glance which code section takes the most time to run.

As with Flamegraph output, one gprof output file is generated for each event configured with a ITRACE_PM_DELTA or ITRACE_PM_NORMALIZED processing mode, as well as time (expressed in microseconds) and pcycles (when relevant). gprof output files contain a flat profile and a call graph report as with the conventional gprof tool.
Here is for example a gprof output for the time metric:
Flat profile for event TIME_NS
% total self total self
total count count calls count/call count/call name
84.35 523317604 511138440 2 261658800.00 255569216.00 Overall section domain 3
9.79 59346968 59346968 30 1978232.25 1978232.25 memcpy
5.02 30396768 30396768 6 5066128.00 5066128.00 itrace_example_float_loop
0.40 4643738 2418752 30 154791.27 80625.07 12345
0.37 2224986 2224986 60000 37.08 37.08 1
0.06 64340710 350004 30 2144690.50 11666.80 itrace_example_copy_bufs
0.02 30505832 109064 6 5084305.50 18177.33 float_loop
Call graph for event TIME_NS
idx % count self children called name
[ 0] NA NA NA 0 root [0]
350004 63990706 24/30 itrace_example_copy_bufs [3]
511138440 12179164 2/2 Overall section domain 3 [5]
109064 30396768 6/6 float_loop [7]
-----------------------------------------------
2418752 2224986 60000/60000 12345 [2]
[ 1] 0.37 2224986 0 60000 1 [1]
-----------------------------------------------
350004 63990706 30/30 itrace_example_copy_bufs [3]
[ 2] 0.77 2418752 2224986 30 12345 [2]
2224986 0 60000/60000 1 [1]
-----------------------------------------------
NA NA 24/30 root [0]
511138440 12179164 6/30 Overall section domain 3 [5]
[ 3] 10.62 350004 63990706 30 itrace_example_copy_bufs [3]
2418752 2224986 30/30 12345 [2]
59346968 0 30/30 memcpy [4]
-----------------------------------------------
350004 63990706 30/30 itrace_example_copy_bufs [3]
[ 4] 9.79 59346968 0 30 memcpy [4]
-----------------------------------------------
NA NA 2/2 root [0]
[ 5] 86.36 511138440 12179164 2 Overall section domain 3 [5]
350004 63990706 6/30 itrace_example_copy_bufs [3]
-----------------------------------------------
109064 30396768 6/6 float_loop [7]
[ 6] 5.02 30396768 0 6 itrace_example_float_loop [6]
-----------------------------------------------
NA NA 6/6 root [0]
[ 7] 5.03 109064 30396768 6 float_loop [7]
30396768 0 6/6 itrace_example_float_loop [6]
-----------------------------------------------
Note there are also gprof-like reports generated for each itrace event. Here is for example a report for the COMMITTED_FPS PMU event:
Flat profile for event 0x50 COMMITTED_FPS
% total self total self total total
total count count calls count/call count/call time(ns)/call count/time(ns) name
42.80 17965016 17965016 30 598833.88 598833.88 1978232.25 0.30271 memcpy
28.60 12004800 12004800 2 6002400.00 6002400.00 261658800.00 0.02294 Overall section domain 3
28.59 12001550 12001550 6 2000258.38 2000258.38 5066128.00 0.39483 itrace_example_float_loop
0.00 12001550 0 6 2000258.38 0.00 5084305.50 0.39342 float_loop
Call graph for event 0x50 COMMITTED_FPS
idx % count self children called name
[ 0] NA NA NA 0 root [0]
NA NA 24/30 itrace_example_copy_bufs [3]
12004800 0 2/2 Overall section domain 3 [5]
0 12001550 6/6 float_loop [7]
-----------------------------------------------
NA NA 60000/60000 12345 [2]
[ 1] NA NA NA 60000 1 [1]
-----------------------------------------------
NA NA 30/30 itrace_example_copy_bufs [3]
[ 2] NA NA NA 30 12345 [2]
NA NA 60000/60000 1 [1]
-----------------------------------------------
NA NA 24/30 root [0]
12004800 0 6/30 Overall section domain 3 [5]
[ 3] NA NA NA 30 itrace_example_copy_bufs [3]
NA NA 30/30 12345 [2]
17965016 0 30/30 memcpy [4]
-----------------------------------------------
NA NA 30/30 itrace_example_copy_bufs [3]
[ 4] 42.80 17965016 0 30 memcpy [4]
-----------------------------------------------
NA NA 2/2 root [0]
[ 5] 28.60 12004800 0 2 Overall section domain 3 [5]
NA NA 6/30 itrace_example_copy_bufs [3]
-----------------------------------------------
0 12001550 6/6 float_loop [7]
[ 6] 28.59 12001550 0 6 itrace_example_float_loop [6]
-----------------------------------------------
NA NA 6/6 root [0]
[ 7] 28.59 0 12001550 6 float_loop [7]
12001550 0 6/6 itrace_example_float_loop [6]
-----------------------------------------------
Please refer to any online documentation on gprof for more details on these reports.
The itrace library is designed to monitor events on various domains.
Event definitions are domain-specific. In the case of the DSP for example, there are four kinds of itrace_event_t.
Note: PMU events are shared globally and may be configured in a number of ways, directly or indirectly:
If itrace is used to monitor PMU events as described below, the user needs to ensure that no other process running on the device modifies the PMU configurations. Otherwise, PMU counter values recorded by itrace will be incorrect, or, instead, will cause the other processes making use of PMU events to behave incorrectly.
Whenever it deregisters events–for example, when the profiler is being closed–itrace checks if the PMU configurations were modified by another process since event registration. If the PMU configurations did not change, the NSP logs will include a message like the following, reporting the PMU configurations that were used by itrace:
PMU configurations have been stable throughout itrace monitoring: QURT_PMUEVTCFG=0x3f034250, QURT_PMUEVTCFG1=0x46, QURT_PMUCFG=0x400
Otherwise, the NSP logs will display a message like the following showing the PMU configurations set by itrace and how those were subsequently modified by another process:
WARNING: PMU configurations have been modified by an instance other than itrace
itrace initial configurations | end configurations
QURT_PMUEVTCFG 000000000000000003f034250 | 00000000000000000463f55cd
QURT_PMUEVTCFG1 0000000000000000000000046 | 0000000000000000011007f03
QURT_PMUCFG 0000000000000000000000400 | 0000000000000000000006000
All published PMU events are defined and supported by the itrace library with the DSP PMU event definitions. For example, if the client registers event id ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY, the library will monitor the number of packets that are committed by any thread.
In the profiling reports generated by the logger, published PMU events are reported both with their names and corresponding opcodes. For example: 0x3:COMMITED_PKT_ANY:.
Note: some events are supported on some architectures and not others. The itrace library will identify at registration time which published events are supported on the domain being monitored and will only register those that are valid. For more details on the registration mechanism, see itrace_register_events.
The client may provide directly as the event_id the opcode of any PMU event, pubished or not. For example, if the client registers event id 0x3 (which corresponds to the same COMMITED_PKT_ANY event as above), the library will monitor the number of packets that are committed by any thread.
In the profiling reports, PMU events registerd by opcodes are reported by their opcodes only. For example: 0x3.
The library includes Non-PMU DSP event definitions. For example, if the client registers event id ITRACE_DSP_EVENT_HEAP_FREE, the library will monitor the number of free bytes of heap memory.
The library supports custom DSP events. These events, identified with id ITRACE_DSP_EVENT_CUSTOM, enable a client to monitor its own set of events. For each custom event, the client is responsible for providing the implementation and its context as part of the itrace_event_t.
Note: Custom events need to be registered from the DSP domain.
The library includes CPU event definitions to monitor CPU events. For example, if the client registers event id ITRACE_CPU_EVENT_CORE_0_CLK_FREQ_HZ, the library will monitor the clock frequency (in Hz) of core 0.
The client can create one profiler instance for each domain. The domains supported today are the DSPs (CDSP, ADSP, etc.) and the application processor (CPU). Each profiler instance maintains its separate log and set of events to monitor. Domains are specified using the IDs defined in the Hexagon SDK remote.h file. Examples of such IDs include CDSP_DOMAIN_ID or ADSP_DOMAIN_ID. To specify a domain not already present in remote.h, such as the CPU domain, use the Domain extensions.
The domain on which a profiler instance runs does not have to be the local domain from which the profiler instance was created. This approach allows a client, for example, to specify from the application processor the start and end of code sections running on the CDSP and have the library monitor CDSP-specific events such as PMU events without having access to the DSP source or requiring any recompilation of the DSP source code.
The library also includes multi-domain support across different processes. For instance, if multiple clients are each using an instance of itrace at the same time, each client may have it's own profiler instance on the same domain (CPU, CDSP, ADSP, etc.). If multiple clients would like to monitor PMU events on the same domain, it is imperative to configure the PMU arbitration policy via itrace_configure_pmu_policy for each client's profiler instance. This policy can also be specified in configuration files via MIN_NUMBER_REGISTERED_PMUS, MAX_NUMBER_REGISTERED_PMUS, and PMU_REGISTRATION_TIMEOUT_US.
All logger-related APIs are described in the Profiler APIs section.
A logger instance is responsible for parsing buffers of events collected by one or more profiler instances and generating output files enabling a user to visualize the activity on one or more domains. Each profiler instance needs to be associated to one profiler instance; a logger instance may be associated to one or more profiler instances.
All logger-related APIs are described in the Logger APIs section.
The itrace library is also capable to run the same code block multiple times in order to capture different events on each run. The multipass support serves multiple purposes. For example, it allows to collect data from a large number of PMUs even though only 8 PMU events may be monitored at a given time on a given DSP. In other cases, it may be useful to monitor events on the same application run multiple times as resource consumption may vary from one run to the next.
Multi-pass runs are supported through an additional couple of macros that extend the core set of the itrace library and that are described in the Multipass extension section.
This section provides a couple of examples where we monitor the same DSP activity in a few different ways.
This example monitors DSP activity from the CPU.
// CPU code
#include "itrace.h"
itrace_logger_handle_t logger_handle;
itrace_open_logger(LOCAL_DOMAIN_ID, &logger_handle); // Note: CPU_DOMAIN_ID would have the same effect
itrace_set_root_filename(logger_handle, "dsp_from_cpu");
itrace_profiler_handle_t profiler_handle;
itrace_open_profiler(logger_handle, CDSP_DOMAIN_ID, 0, &profiler_handle);
itrace_add_event_by_id(profiler_handle,ITRACE_DSP_EVENT_HEAP_FREE); // Monitor how much free heap memory is available
itrace_add_event_by_id(profiler_handle,ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY); // Monitor published PMU event COMMITTED_PKT_ANY=0x3
itrace_add_event_by_id(profiler_handle,0x123); // Monitor unnamed (published or unpublished) PMU event 0x123
int num_registered_events=0;
itrace_event_t attempted_to_register_dsp_events[3];
itrace_register_events(dsp_profiler_handle, attempted_to_register_dsp_events, &num_registered_events);
if (num_registered_events!=3) {
printf("Not all events could be registered. This is unexpected.\n");
return;
}
itrace_start_section(profiler_handle, "DSP section monitored from CPU", NULL);
fastrpc_call_to_dsp_function_foo(); // Call to some DSP function monitored from CPU
itrace_end_section(profiler_handle, NULL);
itrace_flush_logs(logger_handle);
itrace_close_profiler(profiler_handle);
itrace_close_logger(logger_handle);
In this code sample, the client requests itrace to monitor three DSP events when running fastrpc_call_to_dsp_function_foo.
After the code has been executed, the library should have produced a dsp_from_cpu.json trace file and a dsp_from_cpu.csv CSV file. The trace file will show DSP Threads and DSP statistics timelines side by side.
The DSP Thread timeline will show over time when fastrpc_call_to_dsp_function_foo was running. Clicking on it will show the heap memory that was available before and after calling that function, and by how much the published PMU counter COMMITTED_PKT_ANY and the unnamed counter 0x123 increased over the duration of the function. The DSP Statistics timeline will represent the same metrics on thee separate rows (":heap free (B):", "0x3: COMMITTED_PKT_ANY:d", and "0x123::d").
Note how each event name is of the form [id]:[name]:[processing_mode], where each of the field may be omitted if unknown or irrelevant. See itrace_event_t for more details on this format.
This example monitors DSP activity from the DSP itself.
In order to perform the same activity and metrics from within the DSP source, the code above remains almost identical except for the monitoring of the function previously done on the CPU:
// CPU code ... itrace_start_section(profiler_handle, "DSP section monitored from CPU", NULL); fastrpc_call_to_dsp_function_foo(); // Call to DSP function monitored from CPU itrace_end_section(profiler_handle, NULL); ...
becomes
// CPU code
...
fastrpc_call_to_dsp_function_foo(); // Call to DSP function monitored from DSP
...
// DSP code
#include "itrace.h"
...
dsp_function_foo() {
itrace_start_section(NULL, "DSP section monitored from DSP", NULL);
// dsp_function_foo code here
itrace_end_section(NULL, NULL);
}
The output from the itrace library will be similar to what was produced in the first example.
Note that there could be many variations achieving yet the same results:
itrace_profiler_handle_t profiler_handle; itrace_open_profiler(logger_handle, LOCAL_DOMAIN_ID, 0, &profiler_handle);
Specifying a handle to an existing profiler instance instead of passing a NULL
Passing a NULL instructs the library to use the default profiler instance. (Such instance must already have been opened however.) Passing a profiler handle instead allows to monitor independently different applications running on the same domain.
itrace_start_section(profiler_handle, "DSP section monitored from DSP", NULL); // dsp_function_foo code here itrace_end_section(profiler_handle, NULL);
Specifying a pointer to a itrace_measured_events_t instance instad of passing a NULL
Passing a non-null itrace_measured_events_t instance instructs the library that the user needs the measured metrics to be returned programatically. This approach would be used if the user needs to perform some additional processing with the metrics being monitored by itrace in addition to them being captured in the reports.
Hundreds of PMU events are available on each architecture.
Different sets of events enable the user to monitor different areas of the DSP. The events described in this section are useful to provide a usage overview of various areas. All these events are also defined in configs/commonly_used_pmus.txt, which itrace can load using itrace_add_events_from_file.
By default, PMU events accumulate globally: all processes contribute to increasing PMU events. However, some PMUs may be configured to accumulate only for specific threads. This technique is described further below in section STID filtering.
Monitoring the following events will gain insight into how the DSP's compute resources are being used:
CYCLES_1_THREAD_RUNNING CYCLES_2_THREAD_RUNNING CYCLES_3_THREAD_RUNNING CYCLES_4_THREAD_RUNNING CYCLES_5_THREAD_RUNNING CYCLES_6_THREAD_RUNNING COMMITTED_PKT_ANY
In order to monitor these events in itrace, you can load a file with the following contents using itrace_add_events_from_file :
The same can be done programmatically:
itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_1_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_2_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_3_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_4_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_5_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_CYCLES_6_THREAD_RUNNING); itrace_add_event_by_id(dsp_profiler_handle,ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY); itrace_register_events(dsp_profiler_handle, registered_events_array, &num_registered_events);
itrace can monitor up to 8 PMU events at a time. Monitoring more than 8 PMU events at a time can only be done by re-running a block of code multiple times in sets of up to 8 PMU events. This approach allows to get a more complete view of the resource utilization.
With respect to compute power resources, two additional PMU events provide a useful overview, allowing to assess HVX and HMX utilization. If you do not need to measure compute activity when only one thread is running for example, you may want to monitor HVX_ACTIVE and HMX_ACTIVE instead of CYCLES_1_THREAD_RUNNING thus having a of group of 8 events to monitor. Alternatively, you may simply want to monitor all of these PMU events by letting itrace iterate over all added events for the code section identified with the multi-pass APIs ITRACE_MULTI_PASS_START_LOOP and ITRACE_MULTI_PASS_END_LOOP.
The same approach may be followed with the other sets of events described in the next sessions: either restrain yourself to monitoring 8 PMU events at a time, or use the multi-pass approach to monitor a larger number of PMU events by monitoring the same code multiple times with different events.
It may also be useful to combine PMU counters together to obtain derived metrics. (The 'Derived Stats' section of a Hexagon profiler report compute such metrics.)
In this section and all subsequent Derived metrics sections, PMU event names listed in the equations refer to the difference between the counts of the events at the end and start of a monitored code section (calculated with itrace when using the DELTA processing mode).
For example, with:
1T_CPP=CYCLES_1_THREAD_RUNNING/COMMITTED_PKT_1_THREAD_RUNNING
1T_CPP represents the average CPP (Cycle Per Packet) when one thread is running. Similar metrics may be computed for n threads running in parallel, with n between 1 and 6.
The overall CPP may also be computed by dividing the total pcycle count (tracked in itrace as the ITRACE_DSP_EVENT_PCYCLES, or also obtained by adding up all CYCLES_<n>_THREAD_RUNNING counts) by the COMMITTED_PKT_ANY count:
CPP=PCYCLES/COMMITTED_PKT_ANY
CPP metrics are useful to identify code regions where compute resources are underutilized: a high CPP is indicative of code sections with a large number of stalls, which are usually good candidates for optimizations.
Monitoring the following events will gain insights into data traffic between the DSP and DDR:
AXI_LINE256_READ_REQUEST AXI_LINE128_READ_REQUEST AXI_LINE64_READ_REQUEST AXI_LINE32_READ_REQUEST AXI_LINE256_WRITE_REQUEST AXI_LINE128_WRITE_REQUEST AXI_LINE64_WRITE_REQUEST AXI_LINE32_WRITE_REQUEST
The AXI counters may be combined to compute the total number of bytes read from or written to the AXI bus:
AXI_READ_BYTES = AXI_LINE32_READ_REQUEST*32 + AXI_LINE64_READ_REQUEST*64 + AXI_LINE128_READ_REQUEST*128 + AXI_LINE256_READ_REQUEST*256
+ (AXI_READ_REQUEST - AXI_LINE32_READ_REQUEST - AXI_LINE64_READ_REQUEST - AXI_LINE128_READ_REQUEST - AXI_LINE256_READ_REQUEST)*8
AXI_WRITE_BYTES = AXI_LINE32_WRITE_REQUEST*32 + AXI_LINE64_WRITE_REQUEST*64 + AXI_LINE128_WRITE_REQUEST*128
+ (AXI_WRITE_REQUEST - AXI_LINE32_WRITE_REQUEST - AXI_LINE64_WRITE_REQUEST - AXI_LINE128_WRITE_REQUEST)*8
The counters may also be used to compute the total number of bus read and write transactions:
TOTAL_BUS_READS=AXI_READ_REQUEST + AHB_READ_REQUEST TOTAL_BUS_WRITES=AXI_WRITE_REQUEST + AHB_WRITE_REQUEST
Note: You may also want to do a test run of your application monitoring the AXI2_*_REQUEST events listed in itrace_dsp_events_pmu.h that track requests made to the secondary AXI master. If your application uses that master, you will need to include those counters as well in the equations above.
Monitoring the following events will gain insights into HVX usage and what causes it to stall:
HVX_ACTIVE HVX_REG_ORDER HVX_ACC_ORDER HVX_VTCM_OUTSTANDING HVX_LD_L2_OUTSTANDING HVX_ST_L2_OUTSTANDING HVX_ST_FULL HVXST_VTCM_CONFLICT
If using a multi-pass approach is an option, the following expanded group of events is useful to monitor:
HVX_ACTIVE HVX_REG_ORDER HVX_ACC_ORDER HVX_VTCM_OUTSTANDING HVX_LD_L2_OUTSTANDING HVX_ST_L2_OUTSTANDING HVX_ST_FULL HVX_SCATGATH_FULL HVX_SCATGATH_IN_FULL HVXST_VTCM_CONFLICT HVX_VOLTAGE_UNDER HVX_POWER_OVER HVX_VOLTAGE_VIRUS_OVER
Monitoring the following events will gain insights into the use of the scatter-gather processing unit:
SCATGATH_ACTIVE HVX_VTCM_OUTSTANDING SCATGATH_OUTSTANDING HVX_SCATGATH_FULL HVX_SCATGATH_IN_FULL SCATGATHBANK_RD SCATGATHBANK_MODIFY_RD SCATGATHBANK_WR
***Note: *** It is useful to also monitor the additional HVX_ACTIVE event to understand how the scatter-gather activity relates to HVX usage but that does bring the count of PMU events to 9 in one group.
Monitoring the following two sets of events will provide two views on L2 cache utilization:
HVXLD_L2 HVXST_L2 HVXLD_L2_MISS HVXST_L2_MISS HVXLD_L2_SECONDARY_MISS
L2FETCH_ACCESS L2FETCH_MISS L2FETCH_COMMAND L2FETCH_COMMAND_KILLED L2FETCH_COMMAND_OVERWRITE
By default, all processes contribute to increasing PMU counters. However, some PMU counters are maskable. This means that they can be filtered by an STID value, in which case only those NSP threads assigned that STID value will contribute to increasing the corresponding PMU counter. STID values may be shared across multiple threads and range from 1 to 255. STID filtering has no effect on non-maskable events.
Supported values for itrace_stid_t are:
In order to filter all events by an STID value, call itrace_set_stid prior to registering events. In order to filter a specific event by an STID value, set the stid field of the itrace_event_t type used to define an event. Both itrace_set_stid and itrace_add_event return the STID value used by itrace.
itrace leverages the Hexagon compiler Lightweight Instrumentation (LWI) feature to automatically monitor all functions in a DSP source file or library. By default, instrumenting functions with LWI will invoke the itrace_start_section_no_events and itrace_end_section_no_events APIs at the entry and exit points of all functions. These itrace APIs are faster than their counterparts itrace_start_section and itrace_end_section but only monitor time and cycle counts.
You can override this default behavior by including itrace_lwi_with_events.h in your project. This will result in calling itrace_start_section and itrace_end_section at the entry and exit points of all functions instead.
When using LWI, you may want to prevent the compiler from instrumenting functions that only take a few hundreds cycles or less to execute as the overhead added by itrace itself is around a hundred cycles for the fastest API pair that only monitors time and cycle, and a few hundred cycles for the generic APIs also monitoring all registered event. This is accomplished by inserting __attribute__((no_lwi_func)) in the function definition.
Reversely, you may want to select specifically which function to let the compiler instrument with itrace by NOT compiling the code with LWI but instead inserting __attribute__((lwi_func)) in the definitions of all functions that need instrumentation.
The LWI feature and the features discussed above are illustrated in the itrace example.
To enable this feature in any project, take the following steps:
lwi.config and lwiconfig.ini config files to your project from ${ITRACE_DIR}/configs/ and link to the project's DSP skel using the linker flags -Wl,--plugin-config,./lwi.config-flwi-fp -fprofile-lwi-generate-func-latelwi.proto.bin (generated by the Hexagon tools) from the build directory (e.g. $HEXAGON_VARIANT) to the directory pointed to by the EXE_PATH environment variable if it is set, or to the current working directory otherwise.The itrace APIs will add some overhead, between tens and thousands of cycles, when monitoring a code section. The overhead is affected by various factors:
The following sections show detailed overhead numbers measured under various conditions. Here are some high-level observations that may guide you in using itrace APIs most efficiently when running on an NSP:
For time-critical sections, consider the following optimizations:
no_events APIssection_id identifiers for your sections instead of stringsFor example, combining these optimizations with ITRACE_START_SECTION_WITH_CONTEXT_NO_EVENTS and ITRACE_END_SECTION_WITH_CONTEXT_NO_EVENTS leads to an average overhead of 85 cycles to monitor a section. This is the overhead LWI instrumentation adds by default for each monitored function.
The following sections provide overhead numbers measured under different conditions, along with high-level observations to guide efficient use of itrace APIs on a NSP.
*** Note: *** Each of the measurements below is averaged over 1000 iterations and varies by a few percent each time they are collected. These are provided as a rough approximation of the performance overhead to expect in your application.
The following table reports the itrace DSP cycle overhead when monitoring 1 non-PMU event: PCYCLES:0x9000,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 173 | 169 | 4664 |
| start & end_section | 470 | 443 | 2430 |
| start & end_section_with_section_id | 344 | 342 | 2293 |
| START & END_SECTION_WITH_CONTEXT | 299 | 298 | 1710 |
| start & end_section_no_events | 108 | 108 | 783 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 85 | 85 | 948 |
Note: ITRACE_DSP_EVENT_PCYCLES allows to monitor the 64-bit pcycle counter while the no_events itrace API flavors only monitor for free the 32 LSBs of that counter, which is usually sufficient.
When PMU events are measured, the overhead will be significantly lower on v79 NSPs than on older NSP versions, which is why the following sections show the overhead measured on v79 NSPs and pre-v79 NSPs.
The following table reports the itrace DSP cycle overhead when monitoring 1 PMU event: COMMITTED_FPS:0x802d,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 146 | 145 | 2010 |
| start & end_section | 415 | 395 | 2062 |
| start & end_section_with_section_id | 288 | 288 | 923 |
| START & END_SECTION_WITH_CONTEXT | 248 | 247 | 1048 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 281 | 280 | 1933 |
| start & end_section | 706 | 697 | 2710 |
| start & end_section_with_section_id | 566 | 563 | 1316 |
| START & END_SECTION_WITH_CONTEXT | 499 | 498 | 1951 |
The following table reports the itrace DSP cycle overhead when monitoring 2 PMU events: COMMITTED_FPS:0x802d,COMMITTED_PKT_ANY:0x8002,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 164 | 163 | 1616 |
| start & end_section | 443 | 421 | 1756 |
| start & end_section_with_section_id | 317 | 317 | 1123 |
| START & END_SECTION_WITH_CONTEXT | 275 | 274 | 1059 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 441 | 441 | 1219 |
| start & end_section | 1022 | 1022 | 2003 |
| start & end_section_with_section_id | 877 | 877 | 1675 |
| START & END_SECTION_WITH_CONTEXT | 826 | 826 | 1415 |
The following table reports the itrace DSP cycle overhead when monitoring 4 PMU events: COMMITTED_FPS:0x802d,COMMITTED_PKT_ANY:0x8002,AXI_LINE256_READ_REQUEST:0x8104,AXI_LINE256_WRITE_REQUEST:0x80f8,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 161 | 160 | 1617 |
| start & end_section | 429 | 427 | 2037 |
| start & end_section_with_section_id | 320 | 320 | 1184 |
| START & END_SECTION_WITH_CONTEXT | 286 | 282 | 1284 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 731 | 729 | 1472 |
| start & end_section | 1636 | 1632 | 2963 |
| start & end_section_with_section_id | 1505 | 1464 | 3270 |
| START & END_SECTION_WITH_CONTEXT | 1440 | 1436 | 2600 |
The following table reports the itrace DSP cycle overhead when monitoring 8 PMU events: COMMITTED_FPS:0x802d,COMMITTED_PKT_ANY:0x8002,AXI_LINE256_READ_REQUEST:0x8104,AXI_LINE256_WRITE_REQUEST:0x80f8, AXI_LINE128_READ_REQUEST:0x80d7,AXI_LINE128_WRITE_REQUEST:0x80d8,AXI_READ_REQUEST:0x8020,AXI_WRITE_REQUEST:0x8022,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 170 | 169 | 1638 |
| start & end_section | 444 | 442 | 2646 |
| start & end_section_with_section_id | 342 | 341 | 1852 |
| START & END_SECTION_WITH_CONTEXT | 323 | 313 | 1619 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 1359 | 1354 | 2311 |
| start & end_section | 2910 | 2851 | 4395 |
| start & end_section_with_section_id | 2746 | 2741 | 4889 |
| START & END_SECTION_WITH_CONTEXT | 2655 | 2639 | 4640 |
The following sections provide overhead numbers measured under different conditions, along with high-level observations to guide efficient use of itrace APIs on a CPU.
*** Note: *** Each of the measurements below is averaged over 1000 iterations and varies by a few percent each time they are collected. These are provided as a rough approximation of the performance overhead to expect in your application.
The following table reports the itrace CPU cycle overhead when monitoring 1 event: SYSFS_CORE_0_CLK_FREQ_HZ:0x7000,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 399 | 385 | 1135 |
| start & end_section | 805 | 782 | 1159 |
| start & end_section_with_section_id | 762 | 747 | 875 |
| START & END_SECTION_WITH_CONTEXT | 588 | 568 | 1109 |
| start & end_section_no_events | 245 | 244 | 324 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 153 | 152 | 223 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 517 | 323 | 3430 |
| start & end_section | 1319 | 639 | 2467 |
| start & end_section_with_section_id | 1157 | 624 | 2645 |
| START & END_SECTION_WITH_CONTEXT | 625 | 551 | 4091 |
| start & end_section_no_events | 461 | 247 | 2394 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 467 | 240 | 2264 |
The following table reports the itrace CPU cycle overhead when monitoring 8 events: SYSFS_CORE_0_CLK_FREQ_HZ:0x7000,SYSFS_CORE_1_CLK_FREQ_HZ:0x7001,SYSFS_CORE_2_CLK_FREQ_HZ:0x7002,SYSFS_CORE_3_CLK_FREQ_HZ:0x7003, SYSFS_CORE_4_CLK_FREQ_HZ:0x7004,SYSFS_CORE_5_CLK_FREQ_HZ:0x7005,SYSFS_CORE_6_CLK_FREQ_HZ:0x7006,SYSFS_CORE_7_CLK_FREQ_HZ:0x7007,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 1080 | 1027 | 1858 |
| start & end_section | 2154 | 2085 | 3822 |
| start & end_section_with_section_id | 2116 | 2045 | 2710 |
| START & END_SECTION_WITH_CONTEXT | 2021 | 1888 | 3885 |
| start & end_section_no_events | 245 | 244 | 374 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 152 | 151 | 226 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 2543 | 1061 | 26032 |
| start & end_section | 2839 | 2101 | 5880 |
| start & end_section_with_section_id | 2721 | 2066 | 4699 |
| START & END_SECTION_WITH_CONTEXT | 2451 | 1966 | 4130 |
| start & end_section_no_events | 398 | 248 | 2230 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 301 | 229 | 2211 |
The following table reports the itrace CPU cycle overhead when monitoring 1 event: FTRACE_CORE_0_CLK_FREQ_HZ:0x7009,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 195 | 191 | 805 |
| start & end_section | 327 | 322 | 669 |
| start & end_section_with_section_id | 314 | 312 | 343 |
| START & END_SECTION_WITH_CONTEXT | 233 | 225 | 892 |
| start & end_section_no_events | 245 | 244 | 257 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 153 | 151 | 207 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 216 | 203 | 5379 |
| start & end_section | 857 | 391 | 7719 |
| start & end_section_with_section_id | 890 | 359 | 14320 |
| START & END_SECTION_WITH_CONTEXT | 317 | 306 | 1611 |
| start & end_section_no_events | 773 | 246 | 1662 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 388 | 238 | 1640 |
The following table reports the itrace CPU cycle overhead when monitoring 8 events: FTRACE_CORE_0_CLK_FREQ_HZ:0x7009,FTRACE_CORE_1_CLK_FREQ_HZ:0x700a,FTRACE_CORE_2_CLK_FREQ_HZ:0x700b,FTRACE_CORE_3_CLK_FREQ_HZ:0x700c, FTRACE_CORE_4_CLK_FREQ_HZ:0x700d,FTRACE_CORE_5_CLK_FREQ_HZ:0x700e,FTRACE_CORE_6_CLK_FREQ_HZ:0x700f,FTRACE_CORE_7_CLK_FREQ_HZ:0x7010,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 213 | 204 | 906 |
| start & end_section | 369 | 358 | 691 |
| start & end_section_with_section_id | 342 | 329 | 748 |
| START & END_SECTION_WITH_CONTEXT | 264 | 259 | 363 |
| start & end_section_no_events | 245 | 244 | 293 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 152 | 151 | 166 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 437 | 192 | 45037 |
| start & end_section | 1282 | 357 | 5014 |
| start & end_section_with_section_id | 897 | 333 | 2276 |
| START & END_SECTION_WITH_CONTEXT | 498 | 284 | 2392 |
| start & end_section_no_events | 766 | 246 | 2239 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 299 | 240 | 2213 |
The following table reports the itrace CPU cycle overhead when monitoring 1 event: PERF_SW_TASK_CLOCK:0x7012,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 352 | 259 | 860 |
| start & end_section | 713 | 697 | 972 |
| start & end_section_with_section_id | 681 | 670 | 929 |
| START & END_SECTION_WITH_CONTEXT | 474 | 351 | 652 |
| start & end_section_no_events | 245 | 244 | 251 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 153 | 151 | 188 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 496 | 272 | 9698 |
| start & end_section | 551 | 534 | 1092 |
| start & end_section_with_section_id | 1598 | 504 | 2613 |
| START & END_SECTION_WITH_CONTEXT | 800 | 449 | 2412 |
| start & end_section_no_events | 496 | 246 | 2251 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 325 | 238 | 2192 |
The following table reports the itrace CPU cycle overhead when monitoring 1 event: PERF_HW_CACHE_REFERENCES:0x701b,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 351 | 346 | 612 |
| start & end_section | 713 | 698 | 857 |
| start & end_section_with_section_id | 678 | 671 | 749 |
| START & END_SECTION_WITH_CONTEXT | 513 | 424 | 583 |
| start & end_section_no_events | 245 | 244 | 305 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 153 | 152 | 195 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 404 | 276 | 2284 |
| start & end_section | 1379 | 535 | 2481 |
| start & end_section_with_section_id | 1321 | 507 | 2552 |
| START & END_SECTION_WITH_CONTEXT | 466 | 449 | 691 |
| start & end_section_no_events | 1193 | 246 | 2446 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 428 | 238 | 2425 |
The following table reports the itrace CPU cycle overhead when monitoring 8 events: PERF_SW_TASK_CLOCK:0x7012,PERF_SW_PAGE_FAULTS:0x7013,PERF_SW_CONTEXT_SWITCHES:0x7014,PERF_SW_CPU_MIGRATIONS:0x7015, PERF_SW_PAGE_FAULTS_MIN:0x7016,PERF_SW_PAGE_FAULTS_MAJ:0x7017,PERF_HW_CACHE_REFERENCES:0x701b,PERF_HW_CACHE_MISSES:0x701c,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 417 | 405 | 853 |
| start & end_section | 854 | 823 | 3874 |
| start & end_section_with_section_id | 803 | 787 | 2603 |
| START & END_SECTION_WITH_CONTEXT | 694 | 465 | 3649 |
| start & end_section_no_events | 245 | 244 | 303 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 152 | 151 | 194 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 723 | 347 | 2598 |
| start & end_section | 2264 | 690 | 17320 |
| start & end_section_with_section_id | 2444 | 654 | 5753 |
| START & END_SECTION_WITH_CONTEXT | 1553 | 610 | 2777 |
| start & end_section_no_events | 1214 | 246 | 2444 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 490 | 238 | 2421 |
The following table reports the itrace CPU cycle overhead when monitoring 1 event: MEMINFO_MEMTOTAL:0x702f,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 643 | 533 | 2279 |
| start & end_section | 1291 | 1168 | 1483 |
| start & end_section_with_section_id | 1252 | 1143 | 1626 |
| START & END_SECTION_WITH_CONTEXT | 958 | 907 | 1253 |
| start & end_section_no_events | 247 | 244 | 2061 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 153 | 151 | 248 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 847 | 582 | 5743 |
| start & end_section | 2449 | 1143 | 3876 |
| start & end_section_with_section_id | 1444 | 1105 | 3814 |
| START & END_SECTION_WITH_CONTEXT | 1115 | 1052 | 2418 |
| start & end_section_no_events | 1259 | 248 | 2477 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 323 | 239 | 2432 |
The following table reports the itrace CPU cycle overhead when monitoring 8 events: MEMINFO_MEMTOTAL:0x702f,MEMINFO_MEMFREE:0x7030,MEMINFO_MEMAVAILABLE:0x7031,MEMINFO_BUFFERS:0x7032, MEMINFO_CACHED:0x7033,MEMINFO_SWAPCACHED:0x7034,MEMINFO_ACTIVE:0x7035,MEMINFO_INACTIVE:0x7036,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 2293 | 2179 | 3895 |
| start & end_section | 4582 | 4439 | 6230 |
| start & end_section_with_section_id | 4536 | 4367 | 4930 |
| START & END_SECTION_WITH_CONTEXT | 4272 | 4174 | 4513 |
| start & end_section_no_events | 245 | 244 | 309 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 152 | 151 | 217 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 2060 | 1912 | 6854 |
| start & end_section | 5519 | 3805 | 9108 |
| start & end_section_with_section_id | 5557 | 3779 | 7877 |
| START & END_SECTION_WITH_CONTEXT | 3772 | 3696 | 6420 |
| start & end_section_no_events | 692 | 246 | 2446 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 442 | 238 | 2436 |
The following table reports the itrace CPU cycle overhead when monitoring 8 events: SYSFS_CORE_0_CLK_FREQ_HZ:0x7000,SYSFS_CORE_1_CLK_FREQ_HZ:0x7001,FTRACE_CORE_0_CLK_FREQ_HZ:0x7009,FTRACE_CORE_1_CLK_FREQ_HZ:0x700a, PERF_SW_TASK_CLOCK:0x7012,PERF_SW_PAGE_FAULTS:0x7013,MEMINFO_MEMTOTAL:0x702f,MEMINFO_MEMFREE:0x7030,
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 1208 | 1157 | 2515 |
| start & end_section | 2413 | 2347 | 4054 |
| start & end_section_with_section_id | 2349 | 2279 | 2940 |
| START & END_SECTION_WITH_CONTEXT | 2156 | 2033 | 5238 |
| start & end_section_no_events | 247 | 244 | 2100 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 152 | 151 | 322 |
| itrace APIs | avg | min | max |
|---|---|---|---|
| read_events | 1293 | 1153 | 9922 |
| start & end_section | 4048 | 2391 | 10675 |
| start & end_section_with_section_id | 4010 | 2264 | 7253 |
| START & END_SECTION_WITH_CONTEXT | 2367 | 2205 | 5303 |
| start & end_section_no_events | 537 | 246 | 2446 |
| START & END_SECTION_WITH_CONTEXT_NO_EVENTS | 346 | 238 | 2413 |
Both the CPU and DSP itrace libraries are versioned with the following format <ITRACE_VERSION_MAJOR>.<ITRACE_VERSION_MINOR>. The version of the library of each profiler instance is reported in the metadata output file (.txt output).
Note: The itrace library version is different from the library security version, which is used to track security version of the itrace skel. The library security version follows the same format as the library version: <ITRACE_SECURITY_VERSION_MAJOR>.<ITRACE_SECURITY_VERSION_MINOR>
The security version of a skel may be retrieved by running hexagon-llvm-readelf --notes
This section illustrates how to integrate the itrace library into a project.
The following steps are part of the build process:
${HEXAGON_SDK_ROOT}/libs/itrace/prebuilts/<hlos_dir>/libitrace.so and ${HEXAGON_SDK_ROOT}/libs/itrace/deps/protobuf/libprotobuf.so) to the project's HLOS executable.${HEXAGON_SDK_ROOT}/libs/itrace/prebuilts/<dsp_dir>/libritrace_skel.so) to the project's DSP skel. NOTE: Hexagon Simulator is not supported by itrace. When linking the itrace library with a project utilizing Hexagon Simulator, it is necessary to avoid building itrace with the Hexagon Simulator Test Executable.After you have linked the itrace HLOS and DSP binaries, the next step is to configure itrace into a project. There are multiple ways to accomplish this:
itrace.h.itrace_setup_from_file API call takes a setup file (such as the file itrace_config_template.txt provided alongside the library), and sets up an itrace configuration based on the specifications of the file.itrace_teardown API call flushes the logs to the output directory specified by the configuration file passed to itrace_setup_from_file and cleans up itrace.Automating the usage of configuration files
${HEXAGON_SDK_ROOT}/libs/itrace/prebuilts/<hlos_dir>/libitrace_constructor.so to the project's HLOS executable.${HEXAGON_SDK_ROOT}/libs/itrace/prebuilts/<dsp_dir>/libritrace_constructor_skel.so) to the project's DSP skel.DEFAULT_INPUT_FILENAME defined in itrace_types.h.Notes:
There are multiple ways to monitor code regions. Any combination of the following can be used:
itrace_start_section and itrace_end_sectionitrace_start_section_with_section_id and itrace_end_sectionitrace_start_section_no_events and itrace_end_section_no_events-finstrument-functions-after-inlining C/C++ flag when compiling your HLOS code.The following steps are part of the itrace setup process:
${HEXAGON_SDK_ROOT}/libs/itrace/libitrace.so and libprotobuf.so.libritrace_skel.soitrace_config_template.txtlibitrace_constructor.so to the HLOS directory and libritrace_constructor_skel.so to the DSP directory.itrace_set_root_filename API call.A project utilizing the default configuration file (itrace_config_template.txt) will generate an itrace output to the itrace_results folder under the directory from which the application was executed with various output files: itrace_output.json, itrace_output.csv, etc. Refer to the itrace example in the Heagon SDK for more detailed information on the results generated by itrace.
The itrace library is shipped alongside an executable, itrace_monitor. This executable allows a user to monitor CPU and DSP events without the need to instrument any application. Unlike other auto-instrumented approaches discussed above however, this executable is not intended to monitor any thread activity. As a result, device resource usage will be not be correlated to any program activity.
The itrace_monitor executable comes with a wrapper script, itrace_monitor.py which facilitates the process of selecting a device, pushing binaries to target, and retrieving the reports captured by itrace. This script shares the same common interface as the Hexagon SDK examples walkthrough:
$ python3 scripts/itrace_monitor.py -h
usage: itrace_monitor.py [-h] [--prebuilt PREBUILT] [-T] [-B] [-C] [-U] [-D] [-s] [-M] [-N] [-32] [-V] [-DR]
note: One of -T or -s is mandatory for running the script
HLOS argument:
Specify target HLOS (default: LA)
Other arguments:
-h, --help show this help message and exit
--prebuilt PREBUILT, -p PREBUILT
Check itrace tests using prebuilts (default: None)
-T , --target Name of the connected target (default: None)
-B , --build-system Specify the build system (default: cmake)
-C , --build-config Specify the build config (default: None)
-U , --unsigned Run on specified PD: 1 for Unsigned PD and 0 for Signed PD. Default value is 1 for CDSP and 0 for other DSPs (default: None)
-D , --domain Specify the DSP on the device (default: None)
-s , --device-id Device ID. For example, ADB serial number for LA & LE devices (default: None)
-M, --skip-rebuild Do not rebuild (default: False)
-N, --skip-testsig Skip test signature installation (default: False)
-32, --thirty-two-bit
Specify only if the HLOS arch of the target is 32 bit (default: False)
-V, --verbose Enable verbose logging during compilation (default: False)
-DR, --dry-run Print all the commands that the walkthrough would execute without actually running them (default: False)
Once launched, the itrace_monitor executable allows the user to pass in a number of commands to configure itrace and use it to monitor the device.
************************************************************************************************************** *** Welcome to itrace_monitor, a command-line tool leveraging itrace solely to monitor CPU and DSP counters. *** Type `h` and return to get more help.
Each option contains a short and long name, which can be used interchangeably. All supported commands may be listed by entering the h or help command:
************************************************************************************************************** Options: (one-letter and long-version option names are both supported) -------- a,append_events EVENTS Append a set of comma-separated events to the existing ones * d,define_events EVENTS Define a new set of comma-separated events * c,load_configs_from_file FILE Load itrace configurations from file (instead of individual options below) e,end_monitor End itrace monitoring events h,help Show this help message n,num_pmu_slots N_SLOTS Max number of PMU slots to use for registration. Default: 8 o,set_output_filename FILE Set the name of the output file generated by itrace. Default: @itrace_results/itrace_monitor p,set_period PERIOD_US Set the event sampling period (microseconds). Default: 5000 q,quit Quit this program (same as typing `return`) s,start_monitor Start itrace monitoring events x,switch_events N_SAMPLES Number of consecutive samplings of the same set of events. Default: 5000 * First EVENTS field is the domain (CPU, CDSP, ADSP, etc.). Each column-separated event is specified by its name or opcode. If more events are specified that may be monitored at the same time, these events are monitored in sets. A new set is created every N_SAMPLES * PERIOD_US microseconds.
The help menu comes with a simple, self-explanatory sequence of commands that might be executed:
Usage examples: --------------- d CDSP,0x3,0x42 # itrace will monitor PMU events 0x3 and 0x50 on the CDSP domain. (`a` would work the same as `d` here.) a CDSP,ITRACE_DSP_EVENT_PMU_COMMITTED_FPS # itrace will monitor PMU events 0x3, 0x50 and 0x50 (PMU_COMMITTED_FPS) on the CDSP domain d CPU,ITRACE_CPU_EVENT_SYSFS_CORE_0_CLK_FREQ_HZ # itrace will monitor the core 0 clock speed on the CPU domain s # Start monitoring CDSP and CPU activity e # Start monitoring CDSP and CPU activity define_events CDSP,0x3 # itrace will only monitor PMU event 0x3 on the CDSP domain. Same as `d CDSP,0x3` c @itrace_config.txt # itrace will be configured from file <EXE_PATH>/itrace_config.txt. s # Resume monitoring CDSP and CPU activity e # Start monitoring CDSP and CPU activity q # End all monitoring
Note: itrace_monitor is designed to rotate through all events if more events have been defined that can be monitored at a time. For example, if:
itrace_monitor is configured to monitor 10 PMU events, numbered from 1 to 10itrace_monitor can use is set to 41000Then itrace_monitor events will monitor events as follows:
 1.8.13
1.8.13